import datashader as ds
import geopandas as gpd
import rioxarray
import xarray as xr
import osmnx as ox
import pandas as pd
import matplotlib.pyplot as plt
import xvecPopulation as a raster grid
Until now, all the data you were working with were tables. However, not everything is a table. Raster data are not that common in social geography, but spatial data science is full of it, from satellite imagery to population grids. In this session, you will learn how to work with spatial raster data in Python and how to link raster to vector using the ecosystem around the xarray package.
Arrays and their many dimensions
Raster data are represented as arrays. Those can take many forms and shapes. You already know pandas data structures, so let’s start with those.
A pandas.Series is a 1-dimensional array with an index. A typical array contains values of the same data type (e.g. float numbers), as does a typical Series.
When it comes to geospatial raster data, one dimension is not enough. Even the most basic raster, something like a digital terrain model (DTM), requires two dimensions. One represents longitude (or x when projected), while the other latitude (or y), resulting in a 2-dimensional array.
But you don’t have to stop there. Take a typical satellite image. The longitude and latitude dimensions are still present, but you have different bands representing blue, green, red and often near-infra-red frequencies, resulting in a 3-dimensional array (lon, lat, band). Throw in time, and you’re now dealing with a 4-dimensional array (lon, lat, band, time).
All these use cases fall under the umbrella of N-dimensional array handling covered by the xarray package. Whereas a pandas.Series is a 1-dimensional array with an index, xarray.DataArray is an N-dimensional array with N indexes. Combining multiple Series gives you a pandas.DataFrame, where each column can have a different data type (e.g. one numbers, other names). Combining multiple xarray.DataArrays gives you a xarray.Dataset, where each array can have a different data type. There’s a lot of similarity between pandas and xarray, but also some differences.
Let’s read some raster and explore xarray objects in practice.
Population grids
Today, you will be working with the data from the Global Human Settlement Layer (GHSL) developed by the Joint Research Centre of the European Commission. Unlike in all previous hands-on sessions, the data is not pre-processed and you could read it directly from the open data repository. However, since that seems to be a bit unstable lately, use the copy stored as part of this course.
The first layer you will open is a population grid. GHSL covers the whole world divided into a set of tiles, each covering an area of 1,000 by 1,000 km at a resolution of 100m per pixel. The link below points to a single tile1 covering most of Eastern Europe.
1pop_url = (
"https://martinfleischmann.net/sds/raster_data/data/"
"GHS_POP_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip"
)
pop_url- 1
- The URL is long. It may be better to write it as a multi-line string to avoid a long line.
'https://martinfleischmann.net/sds/raster_data/data/GHS_POP_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip'
NoteOriginal data
You can, alternatively, try reading the original data directly using this URL:
pop_url = (
"https://jeodpp.jrc.ec.europa.eu/ftp/jrc-opendata/GHSL/"
"GHS_POP_GLOBE_R2023A/GHS_POP_E2030_GLOBE_R2023A_54009_100/"
"V1-0/tiles/GHS_POP_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip"
)The pop_url points to a ZIP file. Within that ZIP file is a GeoTIFF containing the actual raster. There is often no need to download and unzip the file as there’s a good chance you can read it directly.
Reading rasters with rioxarray
xarray, like pandas is an agnostic library. It is designed for N-dimensional arrays but not necessarily geospatial arrays (although that is often the case…). It means that by default, it is not able to read geospatial file formats like GeoTIFF. That is where rioxarray comes in. It comes with the support of the usual geo-specific things like specific file formats or CRS.
- 1
-
Create a path to the file inside the ZIP. Add the
"zip+"prefix and then the path to the actual file inside the archive, starting with"!". - 2
-
Use
rioxarrayto open the file using the lower-levelrasteriopackage. Withmasked=Trueensure, that the missing values are properly masked out.
<xarray.DataArray (band: 1, y: 10000, x: 10000)> Size: 800MB
[100000000 values with dtype=float64]
Coordinates:
* band (band) int64 8B 1
* y (y) float64 80kB 6e+06 6e+06 6e+06 6e+06 ... 5e+06 5e+06 5e+06
* x (x) float64 80kB 9.59e+05 9.592e+05 ... 1.959e+06 1.959e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0Above, you can see the representation of the population grid as a DataArray. It has three dimensions ("band", "x", "y") with a resolution 1x10,000x10,000 and values as float.
rioxarray gives you a handy .rio accessor on xarray objects, allowing you to access geospatial-specific tools. Like retrieval of CRS.
population.rio.crsCRS.from_wkt('PROJCS["World_Mollweide",GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0],UNIT["Degree",0.0174532925199433]],PROJECTION["Mollweide"],PARAMETER["central_meridian",0],PARAMETER["false_easting",0],PARAMETER["false_northing",0],UNIT["metre",1,AUTHORITY["EPSG","9001"]],AXIS["Easting",EAST],AXIS["Northing",NORTH]]')Or the extent of the raster (in the CRS shown above).
population.rio.bounds()(959000.0, 5000000.0, 1959000.0, 6000000.0)The missing, masked data can be represented as as specific value, especially when dealing with integer arrays. You can check which one:
population.rio.nodatanp.float64(nan)Plotting with datashader
Plotting a raster with a resolution of 10,000x10,000 pixels can be tricky. Often, the resolution is even larger than that. The best way to plot is to resample the data to a smaller resolution that better fits the screen. A handy tool that can do that quickly is datashader. Let’s use it to plot the array as 600x600 pixels.
- 1
- Create a canvas with a specific resolution.
- 2
-
Select pixels with a population more than 0 (
population.where(population>0)), select a single band to get 2-dimensional array (.sel(band=1)) and pass the result to the canvas.
<xarray.DataArray (y: 600, x: 600)> Size: 3MB
array([[4.21513869, 3.52179019, 6.29294423, ..., 1.66938128, 0.82322911,
nan],
[1.04041781, 1.57566844, 4.50548627, ..., nan, 0.15449866,
nan],
[ nan, 3.18057789, 2.21502486, ..., nan, nan,
nan],
...,
[ nan, nan, nan, ..., 4.05967611, 1.9045163 ,
3.70262405],
[ nan, nan, nan, ..., 7.2545469 , 6.44937184,
1.5507871 ],
[ nan, nan, nan, ..., 0.76526973, 1.16737383,
0.21985548]], shape=(600, 600))
Coordinates:
* y (y) float64 5kB 5.999e+06 5.998e+06 ... 5.002e+06 5.001e+06
* x (x) float64 5kB 9.598e+05 9.615e+05 ... 1.957e+06 1.958e+06
Attributes:
res: 100.0
x_range: (np.float64(959000.0), np.float64(1959000.0))
y_range: (np.float64(5000000.0), np.float64(6000000.0))You can see that the result is a new xarray.DataArray with a resolution 600x600. The built-in matplotlib-based plotting can easily handle that.
_ = agg.plot()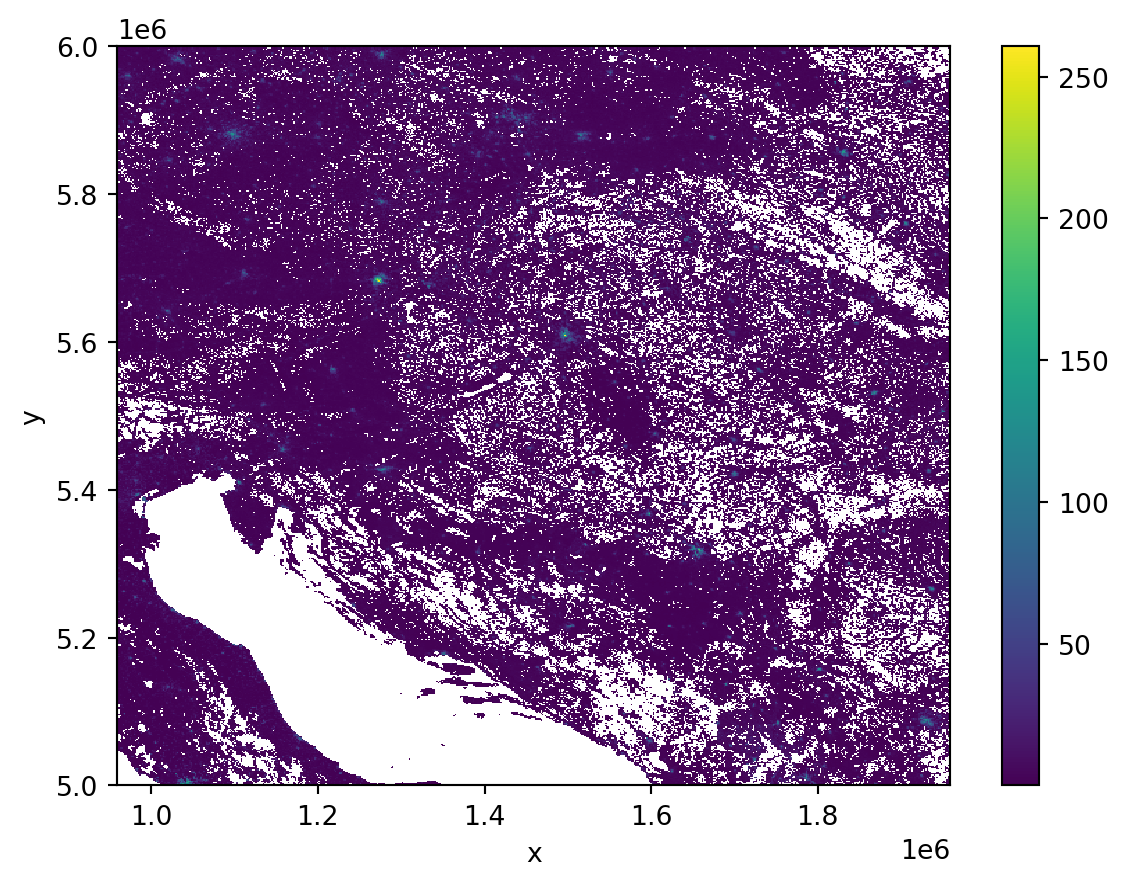
Clipping based on geometry
Daling with large rasters is often impractical if you are interested in a small subset, for example, representing a single city.
Functional Urban Areas
In this case, you may want to work only with the data covering Budapest, Hungary, defined by its functional urban area (FUA), available as another data product on GHSL. FUAs are available as a single GeoPackage with vector geometries.
- 1
- Get the URL.
- 2
- Specify the path to read the file from the ZIP.
- 3
-
Read the table with
geopandas. - 4
- Filter only Budapest.
Make this Notebook Trusted to load map: File -> Trust Notebook
NoteOriginal data
You can, alternatively, try reading the original data directly using this URL:
fua_url = (
"https://jeodpp.jrc.ec.europa.eu/ftp/jrc-opendata/GHSL/"
"GHS_FUA_UCDB2015_GLOBE_R2019A/V1-0/"
"GHS_FUA_UCDB2015_GLOBE_R2019A_54009_1K_V1_0.zip"
)If you want to clip the population raster to the extent of Budapest FUA, you can use the clip method from the rioxarray extension of xarray.
- 1
-
Use
.rio.clipto clip the geospatial raster to the extent of a geometry. - 2
-
Ensure the
budapestis in the same CRS as thepopulationand pass its geometry.
<xarray.DataArray (band: 1, y: 840, x: 830)> Size: 6MB
array([[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]], shape=(1, 840, 830))
Coordinates:
* band (band) int64 8B 1
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The raster is no longer 10,000x10,000 pixels but only 840x830, covering the extent of Budapest FUA. You can easily check that by plotting the clipped array.
_ = population_bud.plot()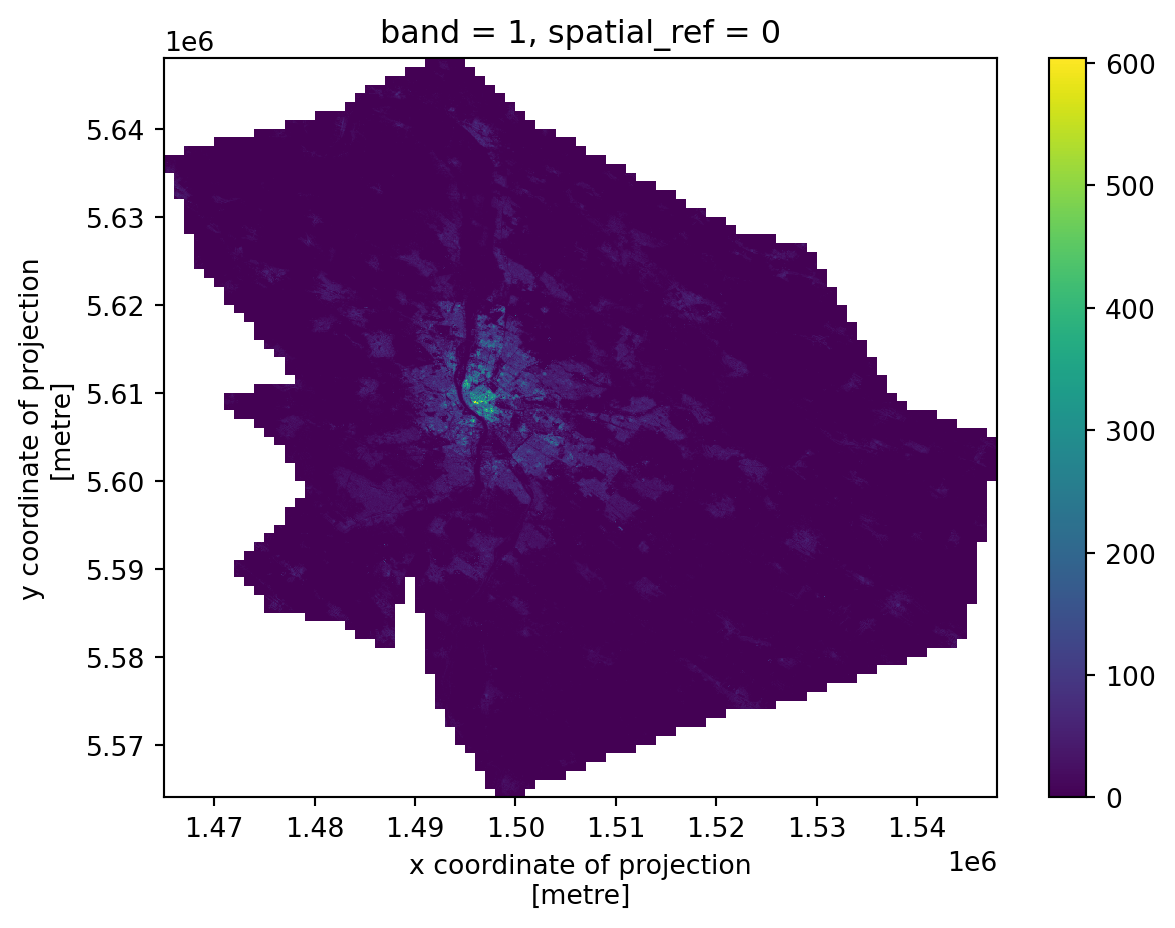
Array manipulation
While this is technically a 3-dimensional array, the dimension "band" has only one value. Normally, you would get a 2-dimensional array representing a selected band using the .sel() method.
population_bud.sel(band=1)<xarray.DataArray (y: 840, x: 830)> Size: 6MB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], shape=(840, 830))
Coordinates:
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
band int64 8B 1
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0But if you have only one band, you can squeeze the array and get rid of that dimension that is not needed.
population_bud = population_bud.drop_vars("band").squeeze()
population_bud<xarray.DataArray (y: 840, x: 830)> Size: 6MB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], shape=(840, 830))
Coordinates:
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0Now a lot what you know from pandas works equally in xarray. Getting the minimum:
population_bud.min()<xarray.DataArray ()> Size: 8B
array(0.)
Coordinates:
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0As expected, there are some cells with no inhabitants.
population_bud.max()<xarray.DataArray ()> Size: 8B
array(603.90405273)
Coordinates:
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The densest cell, on the other hand, has more than 600 people per hectare.
population_bud.mean()<xarray.DataArray ()> Size: 8B
array(6.77593517)
Coordinates:
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0Mean is, however, only below 7.
population_bud.median()<xarray.DataArray ()> Size: 8B
array(0.)
Coordinates:
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0While the median is 0, there are a lot of cells with 0.
TipDataArray vs scalar
Notice that xarray always returns another DataArray even with a single value. If you want to get that scalar value, you can use .item().
population_bud.mean().item()6.775935172506019You can plot the distribution of values across the array.
_ = population_bud.plot.hist(bins=100)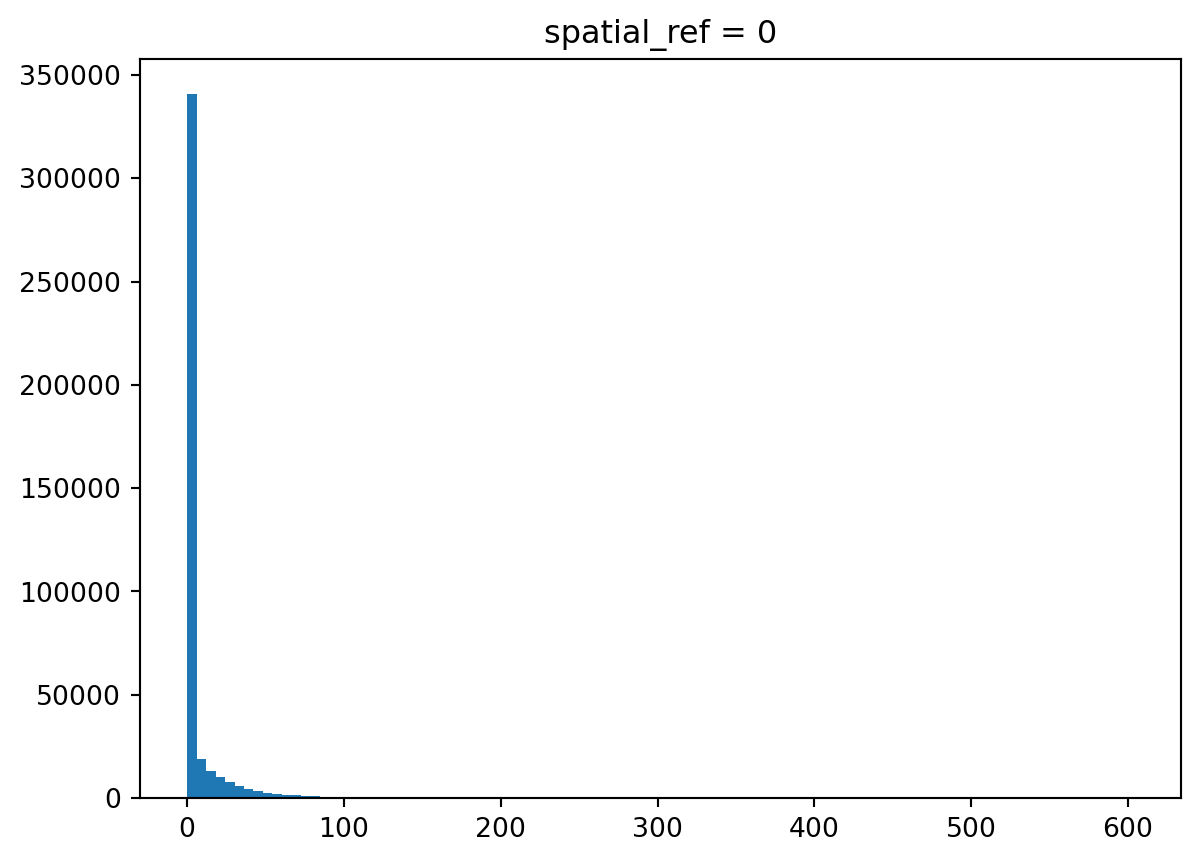
Indeed, there are a lot of zeros. Let’s filter them out and check the distribution again.
_ = population_bud.where(population_bud>0).plot.hist(bins=100)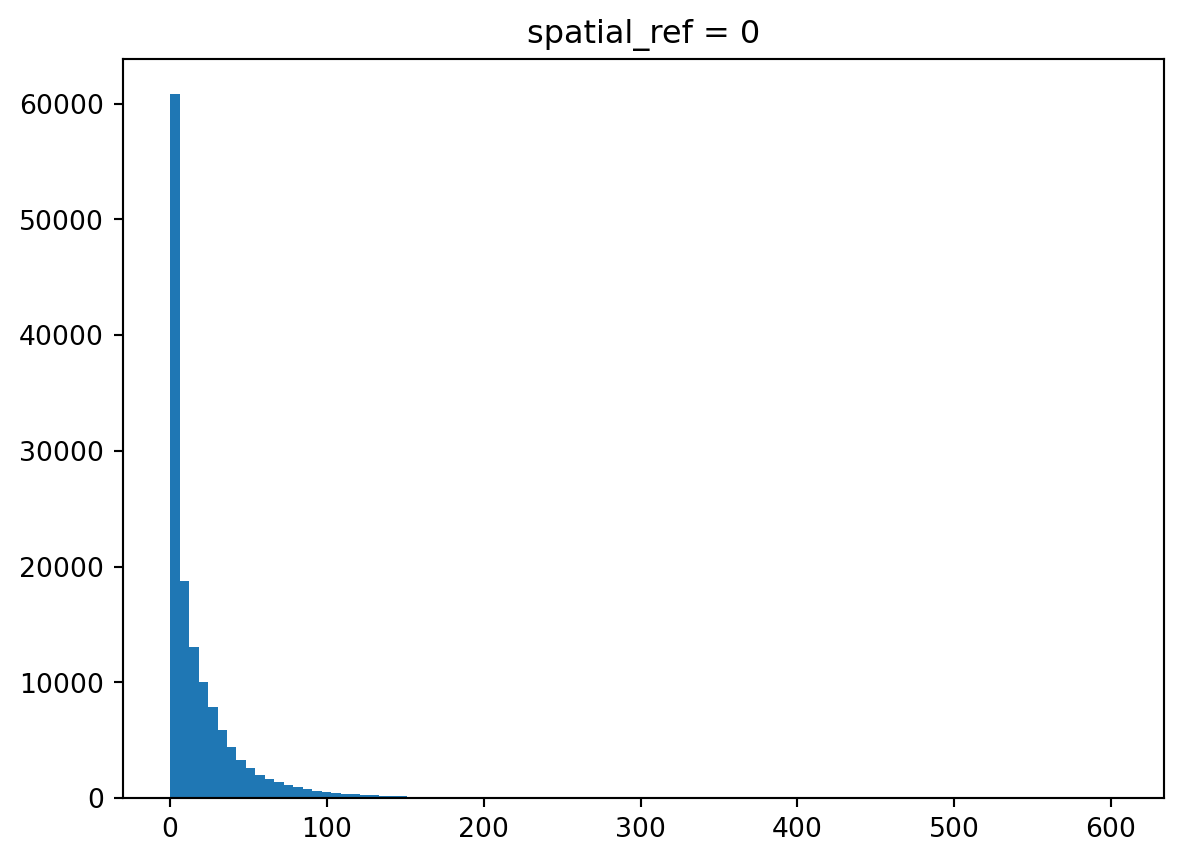
As with many observations in urban areas, this follows a power-law-like distribution with a lot of observations with tiny values and only a few with large ones.
Array operations
Let’s assume that you want to normalise population counts by the built-up volume, which is available as another GHSL product. This time, on a grid again.
volume_url = (
"https://martinfleischmann.net/sds/raster_data/data/"
"GHS_BUILT_V_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip"
)
volume_url'https://martinfleischmann.net/sds/raster_data/data/GHS_BUILT_V_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip'
NoteBackup data
You can, alternatively, try reading the original data directly using this URL:
volume_url = (
"https://jeodpp.jrc.ec.europa.eu/ftp/jrc-opendata/GHSL/"
"GHS_BUILT_V_GLOBE_R2023A/GHS_BUILT_V_E2030_GLOBE_R2023A_54009_100/V1-0/tiles/"
"GHS_BUILT_V_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.zip"
)All work the same as before. You read the GeoTIFF as a DataArray.
p = f"zip+{volume_url}!GHS_BUILT_V_E2030_GLOBE_R2023A_54009_100_V1_0_R4_C20.tif"
built_up = rioxarray.open_rasterio(p, masked=True).drop_vars("band").squeeze()
built_up<xarray.DataArray (y: 10000, x: 10000)> Size: 800MB
[100000000 values with dtype=float64]
Coordinates:
* y (y) float64 80kB 6e+06 6e+06 6e+06 6e+06 ... 5e+06 5e+06 5e+06
* x (x) float64 80kB 9.59e+05 9.592e+05 ... 1.959e+06 1.959e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0And clip it to the same extent.
built_up_bud = built_up.rio.clip(budapest.to_crs(built_up.rio.crs).geometry)
built_up_bud<xarray.DataArray (y: 840, x: 830)> Size: 6MB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], shape=(840, 830))
Coordinates:
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0You can quickly check what it looks like.
_ = built_up_bud.plot(cmap="magma_r")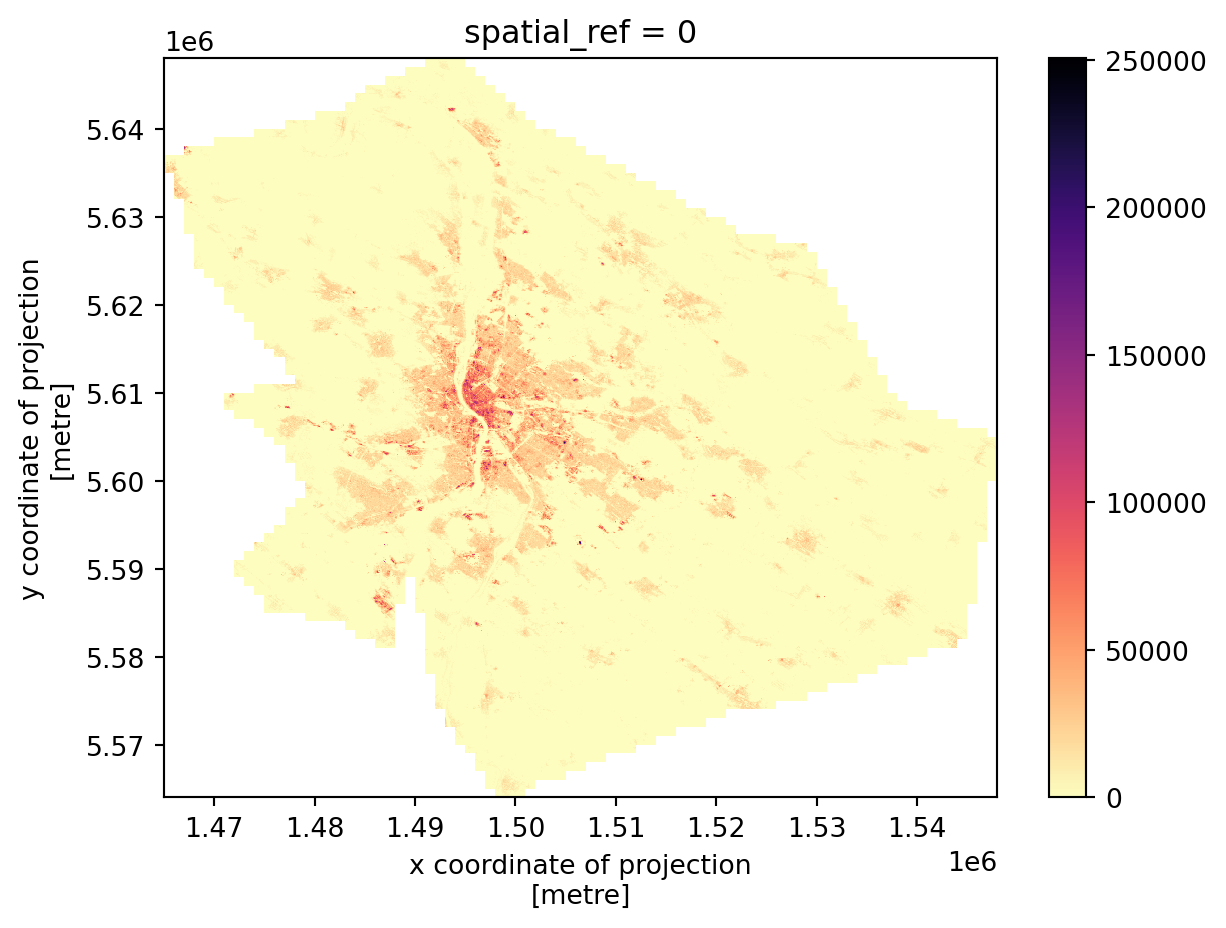
The two grids are aligned, meaning that pixels with the same coordinates represent the same area. This allows us to directly perform array algebra. Again, you know this from pandas.
1pop_density = population_bud / built_up_bud
pop_density- 1
- Divide the population by built-up volume to get a normalised value.
<xarray.DataArray (y: 840, x: 830)> Size: 6MB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], shape=(840, 830))
Coordinates:
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The result is a new array that inherits spatial information (spatial_ref) but contains newly computed values.
_ = pop_density.plot(cmap="cividis_r")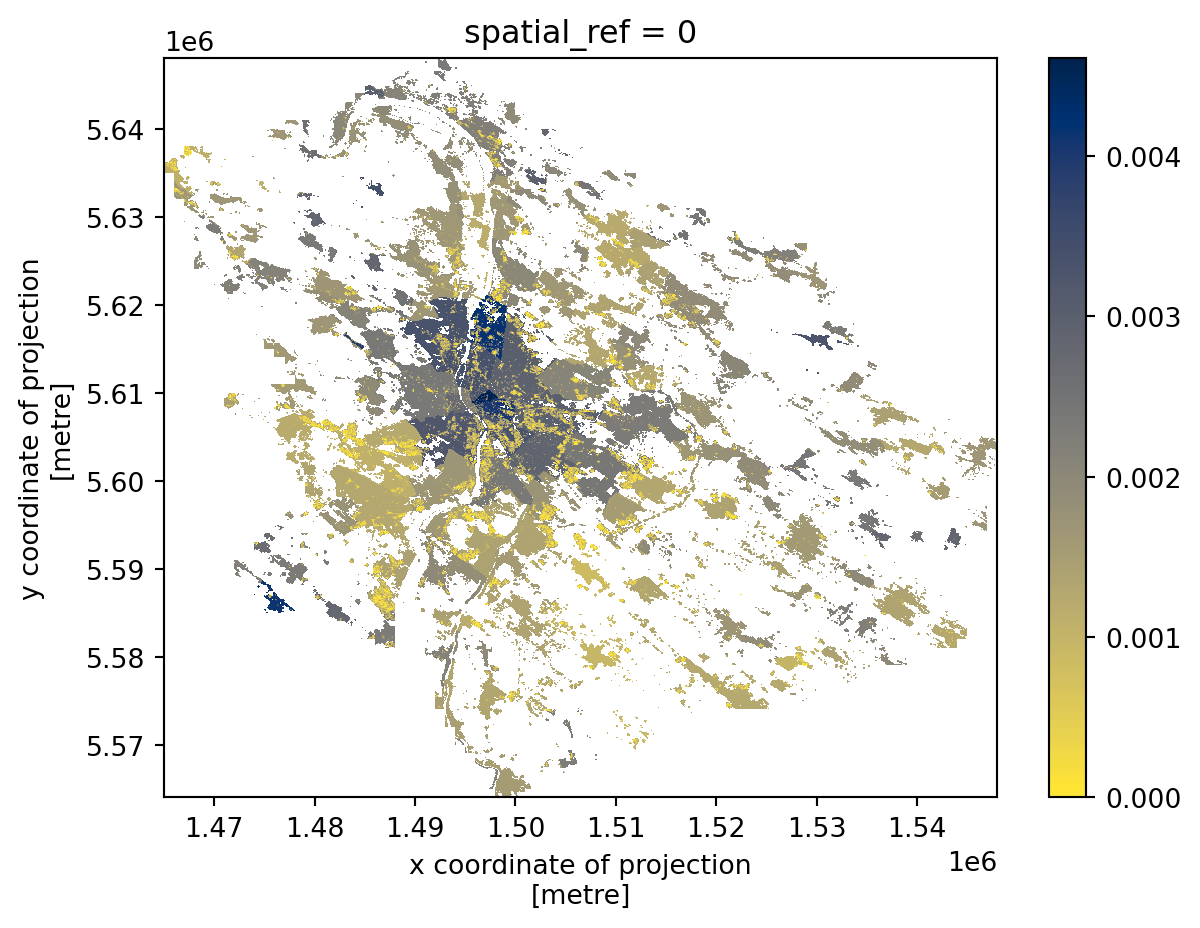
The resulting array can then be saved to a GeoTIFF using rioxarray.
pop_density.rio.to_raster("population_density.tif")Extracting values for locations
A common need is to extract values from raster data for a specific location of interest. That is a first type of interaction between raster and vector data (points in this case). To illustrate the use case, create a set of random points covering the area of budapest.
1locations = budapest.sample_points(1000).explode(ignore_index=True)
locations.head()- 1
-
sample_points()method creates a random sample of the selected size within each geometry in aGeoSeries. Each sample set is aMultiPointbut in this case, you want individual points. That is whenexplode()is useful, since it explodes each multi-part geometry into individual points. Because you are not interested in the original index, you can useignore_index=Trueto get the defaultpd.RangeIndex.
0 POINT (1465290.69 5635257.664)
1 POINT (1465360.288 5635549.644)
2 POINT (1466106.419 5635054.507)
3 POINT (1466587.728 5634977.877)
4 POINT (1467407.682 5637770.743)
Name: sampled_points, dtype: geometryCheck how the sample looks on a map.
locations.explore()Make this Notebook Trusted to load map: File -> Trust Notebook
NoteRandom sampling and reproducibility
The points sampled from budapest will be different every time you run the sample_points() method. If you want to fix the result, you can pass a seed value to a random number generator as rng=42. With the same seed value, the result will be always the same. This is useful, especially if you are interested in the reproducibility of your code.
The xarray ecosystem offers many ways of extracting point values. Below, you will use the implementation from the xvec package. Create a new xarray.DataArray with all three arrays you created so far to see the benefits of using xvec below.
- 1
-
Use
xr.concatfunction to concatenate all arrays together. - 2
- Specify which arrays shall be concatenated.
- 3
-
Define a new dimension created along the axis of concatenation. Use the
pd.Indexto create a new index along this dimension. - 4
- Specify coordinates along the new dimension.
- 5
- Give the dimension a name.
<xarray.DataArray (measurement: 3, y: 840, x: 830)> Size: 17MB
array([[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]], shape=(3, 840, 830))
Coordinates:
* measurement (measurement) StringDType(na_object=nan) 48B 'density' ... '...
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The resulting DataArray is 3-dimensional, compared to 2-dimensional arrays used before. Apart from x and y, you now have measurement as well. Using the new index created above, you can use the sel() method to get the original arrays.
bud_cube.sel(measurement="density")<xarray.DataArray (y: 840, x: 830)> Size: 6MB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], shape=(840, 830))
Coordinates:
* y (y) float64 7kB 5.648e+06 5.648e+06 ... 5.564e+06 5.564e+06
* x (x) float64 7kB 1.465e+06 1.465e+06 ... 1.548e+06 1.548e+06
spatial_ref int64 8B 0
measurement StringDType(na_object=nan) 16B 'density'
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0Now it is time to take this cube and create another based on your points. That can be done using the .xvec accessor and its extract_points method.
- 1
-
Drop
spatial_refbecause it is not interesting for point extraction and use.xvec.extract_points() - 2
- Specify the points for which you want to extract the values.
- 3
-
Specify which dimension of the
bud_cubeDataArrayrepresents x-coordinate dimension of geometries and which represents the y-coordinate dimension to match points to the array.
<xarray.DataArray (measurement: 3, geometry: 1000)> Size: 24kB
array([[1.11217133e-03, 1.11217132e-03, 1.11217132e-03, ...,
1.67070976e-03, nan, 1.67070976e-03],
[2.11245823e+01, 1.98222294e+01, 8.51923227e-01, ...,
3.30800533e-01, 0.00000000e+00, 1.26973942e-01],
[1.89940000e+04, 1.78230000e+04, 7.66000000e+02, ...,
1.98000000e+02, 0.00000000e+00, 7.60000000e+01]], shape=(3, 1000))
Coordinates:
* measurement (measurement) StringDType(na_object=nan) 48B 'density' ... '...
* geometry (geometry) object 8kB POINT (1465290.690260424 5635257.66429...
Indexes:
geometry GeometryIndex (crs=ESRI:54009)
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The resulting object is still a DataArray but a bit different. It is no longer 3-dimensional, although all dimensions of interest ('density', 'population', 'built-up volume') are still there, but 2-dimensional. One dimension is measurement, and the other is geometry, containing the points of interest. With xvec, the spatial dimension is reduced, but the remaining dimensionality of the original array is preserved.
You can then convert the data into a geopandas.GeoDataFrame and work with it as usual.
location_data = vector_cube.xvec.to_geopandas()
location_data.head()| measurement | geometry | density | population | built-up volume |
|---|---|---|---|---|
| 0 | POINT (1465290.69 5635257.664) | 0.001112 | 21.124582 | 18994.0 |
| 1 | POINT (1465360.288 5635549.644) | 0.001112 | 19.822229 | 17823.0 |
| 2 | POINT (1466106.419 5635054.507) | 0.001112 | 0.851923 | 766.0 |
| 3 | POINT (1466587.728 5634977.877) | NaN | 0.000000 | 0.0 |
| 4 | POINT (1467407.682 5637770.743) | 0.000392 | 2.993965 | 7628.0 |
Check the result on a map to verify that all worked as expected.
location_data.explore("density", cmap="cividis_r", tiles="CartoDB Positron")Make this Notebook Trusted to load map: File -> Trust Notebook
NoteVector data cubes
The data structure vector_cube represents is called a vector data cube. It is a special case of an xarray N-dimensional object, where at least one dimension is indexed by geometries. See more in the Xvec documentation.
Zonal statistics
Another operation when working with rasters is the transfer of values from an array to a set of polygons. This is called zonal statistics and can be done in many ways, depending on the use case. In most cases, one of the methods available in xvec should cover your specific needs.
Downloading OpenStreetMap data
You may be interested in the average population density in individual districts of Budapest. One option for getting the geometries representing the districts is the OpenStreetMap. Everything you can see on OpenStreetMap is downloadable. In Python, a recommended way (when not doing large downloads) is the osmnx package (imported as ox). The detailed explanation of osmnx is out of scope for this session, but if you are interested in details, check the official Getting started guide.
- 1
-
Use
features_from_placeto download features from Budapest. But filter only those tagged with theadmin_levelequal to 9. - 2
-
Filter only polygons. The
GeoDataFramecoming fromosmnxalso contains many LineStrings. - 3
- Retain only three columns that may be useful.
- 4
- Ensure the geometry uses the same CRS as the grid.
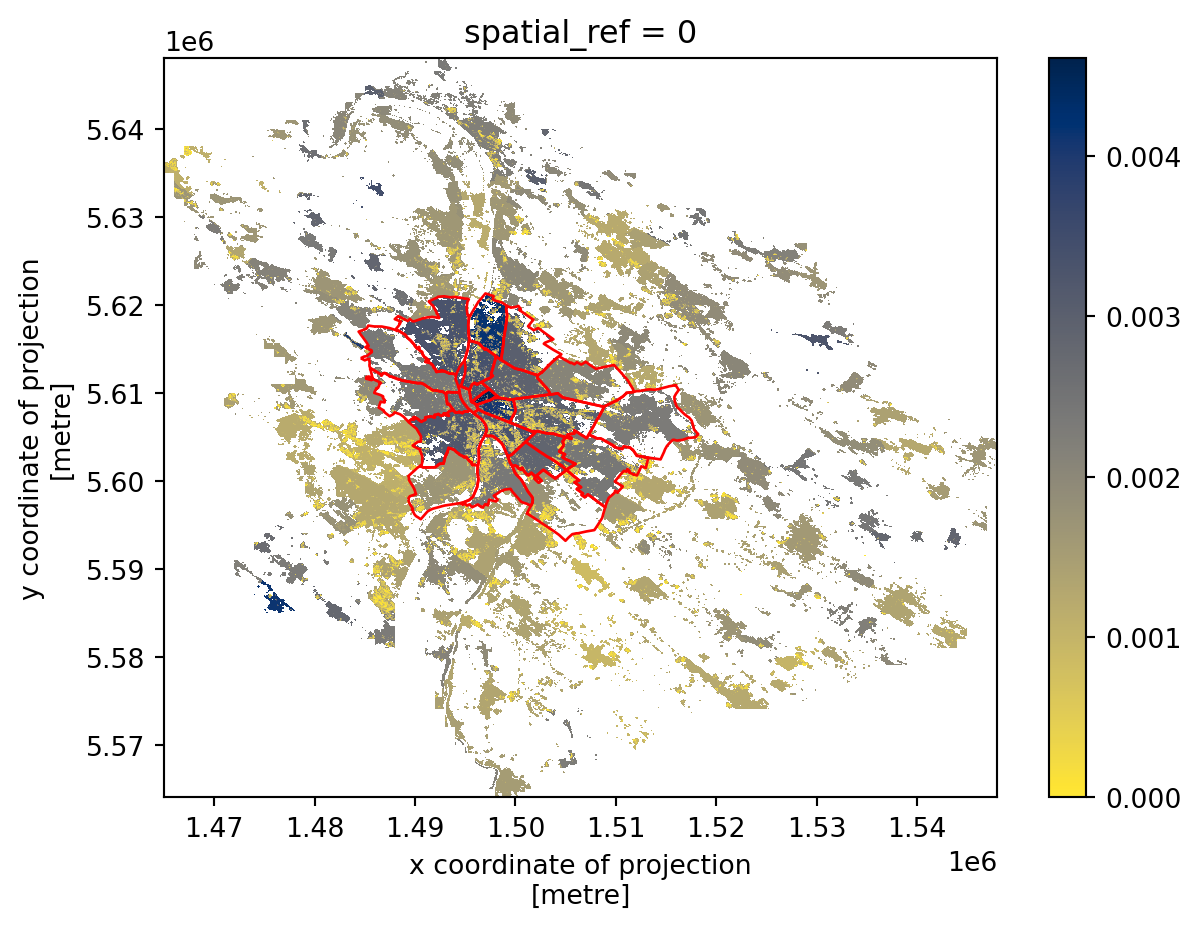
Plotting raster and vector together
Both xarray and geopandas can create matplotlib plots that can be combined to see how the two overlap.
- 1
- Create an empty figure and an axis.
- 2
- Plot the population density to the axis.
- 3
-
Plot the
districtsto the same array, ensuring it is in the same projection. - 4
-
Specify the plotting style and disable the automatic setting of the aspect to keep the axis as returned by
xarray.
Zonal statistics
Zonal statistics using xvec is as simple as point data extraction, with the only difference that you can optionally specify the type of aggregation you’d like to extract. By default, you get mean.
- 1
-
Drop
spatial_refbecause it is not interesting for point extraction and use.xvec.zonal_stats() - 2
- Specify the geometries for which you want to aggregate the values.
- 3
-
Specify which dimension of the
bud_cubeDataArrayrepresents x-coordinate dimension of geometries and which represents the y-coordinate dimension to match geometries to the array.
<xarray.DataArray (geometry: 23, measurement: 3)> Size: 552B
array([[1.93530445e-03, 3.05514687e+01, 1.93385830e+04],
[1.55295374e-03, 1.75246151e+01, 1.24466458e+04],
[2.97506161e-03, 3.44719134e+01, 1.28150591e+04],
[2.28697497e-03, 2.57763161e+01, 1.15085435e+04],
[2.57555294e-03, 7.60535959e+01, 3.06620828e+04],
[2.23885448e-03, 2.30685424e+01, 1.07351248e+04],
[2.64076219e-03, 4.61642623e+01, 2.03001192e+04],
[3.38977582e-03, 5.35142704e+01, 1.77673289e+04],
[1.47557004e-03, 5.79631789e+00, 5.26320947e+03],
[2.10694012e-03, 2.73223607e+01, 1.37756218e+04],
[2.15614865e-03, 1.65916271e+01, 7.80771904e+03],
[2.56786753e-03, 6.79190265e+01, 2.69252700e+04],
[2.67075964e-03, 5.70909834e+01, 2.16905234e+04],
[2.13192067e-03, 5.39063990e+01, 3.07695679e+04],
[2.13384957e-03, 2.67868574e+01, 1.63365941e+04],
[1.95306643e-03, 2.28662318e+01, 1.21904109e+04],
[2.78713051e-03, 1.05099081e+02, 4.07332861e+04],
[2.46986944e-03, 3.14801382e+01, 1.33601201e+04],
[2.62209009e-03, 7.51648089e+01, 3.01167759e+04],
[3.09326745e-03, 1.20672956e+02, 4.17646895e+04],
[2.89497635e-03, 1.67700965e+02, 6.04019202e+04],
[4.16208535e-03, 2.86557806e+02, 6.89801196e+04],
[2.16750490e-03, 1.07272769e+02, 5.10662252e+04]])
Coordinates:
* geometry (geometry) geometry 184B POLYGON ((1494534.3281858459 559745...
index (geometry) object 184B ('relation', 215618) ... ('relation',...
* measurement (measurement) StringDType(na_object=nan) 48B 'density' ... '...
Indexes:
geometry GeometryIndex (crs=ESRI:54009)
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0The result is again a vector data cube. Though mean is not the optimal aggregation method for population. Let’s refine the code above a bit to get more useful aggregation.
zonal_stats = bud_cube.drop_vars("spatial_ref").xvec.zonal_stats(
geometry=districts.geometry,
x_coords="x",
y_coords="y",
3 stats=["mean", "sum", "median", "min", "max"],
)
zonal_stats- 3
-
Specify which aggregations should
xvecreturn as a list.
<xarray.DataArray (geometry: 23, zonal_statistics: 5, measurement: 3)> Size: 3kB
array([[[1.93530445e-03, 3.05514687e+01, 1.93385830e+04],
[4.32734075e+00, 8.02281569e+04, 5.07831190e+07],
[2.37775026e-03, 2.24578524e+01, 1.65745000e+04],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[3.31672247e-03, 2.00829544e+02, 1.49180000e+05]],
[[1.55295374e-03, 1.75246151e+01, 1.24466458e+04],
[4.03767973e+00, 5.88827066e+04, 4.18207300e+07],
[1.70373389e-03, 9.53324318e+00, 7.52950000e+03],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[3.21869412e-03, 1.23922935e+02, 1.45769000e+05]],
[[2.97506161e-03, 3.44719134e+01, 1.28150591e+04],
[9.94265592e+00, 1.35336732e+05, 5.03119220e+07],
[3.32938274e-03, 2.29461060e+01, 8.72550000e+03],
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[3.32938297e-03, 2.58037140e+02, 1.11725000e+05]],
[[2.28697497e-03, 2.57763161e+01, 1.15085435e+04],
[5.62138448e+00, 9.38515669e+04, 4.19026070e+07],
...
[0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[4.60847702e-03, 4.85453461e+02, 1.42089000e+05]],
[[2.89497635e-03, 1.67700965e+02, 6.04019202e+04],
[6.89004371e-01, 3.99128297e+04, 1.43756570e+07],
[3.32703483e-03, 1.75985176e+02, 6.15670000e+04],
[8.24321432e-05, 8.12120438e-01, 2.39000000e+02],
[3.39799356e-03, 3.92064453e+02, 1.91005000e+05]],
[[4.16208535e-03, 2.86557806e+02, 6.89801196e+04],
[8.69875838e-01, 5.98905814e+04, 1.44168450e+07],
[4.60847672e-03, 2.81716187e+02, 6.67140000e+04],
[9.78207908e-04, 5.82796707e+01, 2.87110000e+04],
[4.60847708e-03, 6.03904053e+02, 1.33828000e+05]],
[[2.16750490e-03, 1.07272769e+02, 5.10662252e+04],
[5.13698662e-01, 2.81054655e+04, 1.33793510e+07],
[2.29921378e-03, 1.14399685e+02, 5.84525000e+04],
[8.85650581e-04, 0.00000000e+00, 0.00000000e+00],
[4.60847706e-03, 3.44663391e+02, 1.15273000e+05]]])
Coordinates:
* geometry (geometry) geometry 184B POLYGON ((1494534.3281858459 5...
index (geometry) object 184B ('relation', 215618) ... ('relat...
* zonal_statistics (zonal_statistics) <U6 120B 'mean' 'sum' ... 'min' 'max'
* measurement (measurement) StringDType(na_object=nan) 48B 'density' ...
Indexes:
geometry GeometryIndex (crs=ESRI:54009)
Attributes:
AREA_OR_POINT: Area
scale_factor: 1.0
add_offset: 0.0You may have noticed that our data cube now has one more dimension zonal_statistics, reflecting each of the aggregation methods specified above.
TipOther statistics
The stats keyword is quite flexible and allows you to pass even your custom functions. Check the documentation for details.
To check the result on a map, convert the data to a geopandas.GeoDataFrame again.
zones = zonal_stats.xvec.to_geodataframe(name="stats")
zones| geometry | index | stats | ||
|---|---|---|---|---|
| zonal_statistics | measurement | |||
| mean | density | POLYGON ((1494534.328 5597452.839, 1494709.464... | (relation, 215618) | 0.001935 |
| population | POLYGON ((1494534.328 5597452.839, 1494709.464... | (relation, 215618) | 30.551469 | |
| built-up volume | POLYGON ((1494534.328 5597452.839, 1494709.464... | (relation, 215618) | 19338.583016 | |
| sum | density | POLYGON ((1494534.328 5597452.839, 1494709.464... | (relation, 215618) | 4.327341 |
| population | POLYGON ((1494534.328 5597452.839, 1494709.464... | (relation, 215618) | 80228.156869 | |
| ... | ... | ... | ... | ... |
| min | population | POLYGON ((1494292.33 5610780.086, 1494393.558 ... | (relation, 1606103) | 0.000000 |
| built-up volume | POLYGON ((1494292.33 5610780.086, 1494393.558 ... | (relation, 1606103) | 0.000000 | |
| max | density | POLYGON ((1494292.33 5610780.086, 1494393.558 ... | (relation, 1606103) | 0.004608 |
| population | POLYGON ((1494292.33 5610780.086, 1494393.558 ... | (relation, 1606103) | 344.663391 | |
| built-up volume | POLYGON ((1494292.33 5610780.086, 1494393.558 ... | (relation, 1606103) | 115273.000000 |
345 rows × 3 columns
Check the result on a map to verify that all worked as expected. Get mean density and explore its values, stored in the stats column.
zones.loc[("mean", 'density')].explore("stats", cmap="cividis_r", tiles="CartoDB Positron")/tmp/ipykernel_3917/4164103204.py:1: PerformanceWarning: indexing past lexsort depth may impact performance.
zones.loc[("mean", 'density')].explore("stats", cmap="cividis_r", tiles="CartoDB Positron")Make this Notebook Trusted to load map: File -> Trust Notebook
TipAdditional reading
Have a look at the chapter Local Spatial Autocorrelation from the Geographic Data Science with Python by Rey et al. (2023) to learn how to do LISA on rasters.
The great resource on xarray is their tutorial.
References
Rey, Sergio, Dani Arribas-Bel, and Levi John Wolf. 2023. Geographic Data Science with Python. Chapman & Hall/CRC Texts in Statistical Science. Taylor & Francis.
Footnotes
See the distribution of tiles in the data repository.↩︎