Similar data belong together
Everything should be made as simple as possible, but not simpler
Albert Einstein
The need to group data
The world is complex and multidimensional
Univariate analysis focuses on only one dimension
Sometimes, world issues are best understood as multivariate
For example
Percentage of foreign-born vs What is a neighborhood?
Years of schooling vs Human development
Monthly income vs Deprivation
Grouping as simplifying
Define a given number of categories based on
many characteristics (multi-dimensional)
Find the category where each observation fits best.
Reduce complexity, keep all the relevant information
Produce easier-to-understand outputs
Types of grouping
Non-spatial clustering
Regionalisation
Non-spatial clustering
Split a dataset into groups of observations that are similar within the group
and dissimilar between groups based on a series of attributes
Machine learning
The computer learns some of the dataset’s properties without the human specifying them.
Unsupervised
There is no apriori structure imposed on the classification \(\rightarrow\) before the analysis, no observations are in a category.
K-means
Most popular clustering algorithm
Good but not perfect
partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid)
Wikipedia
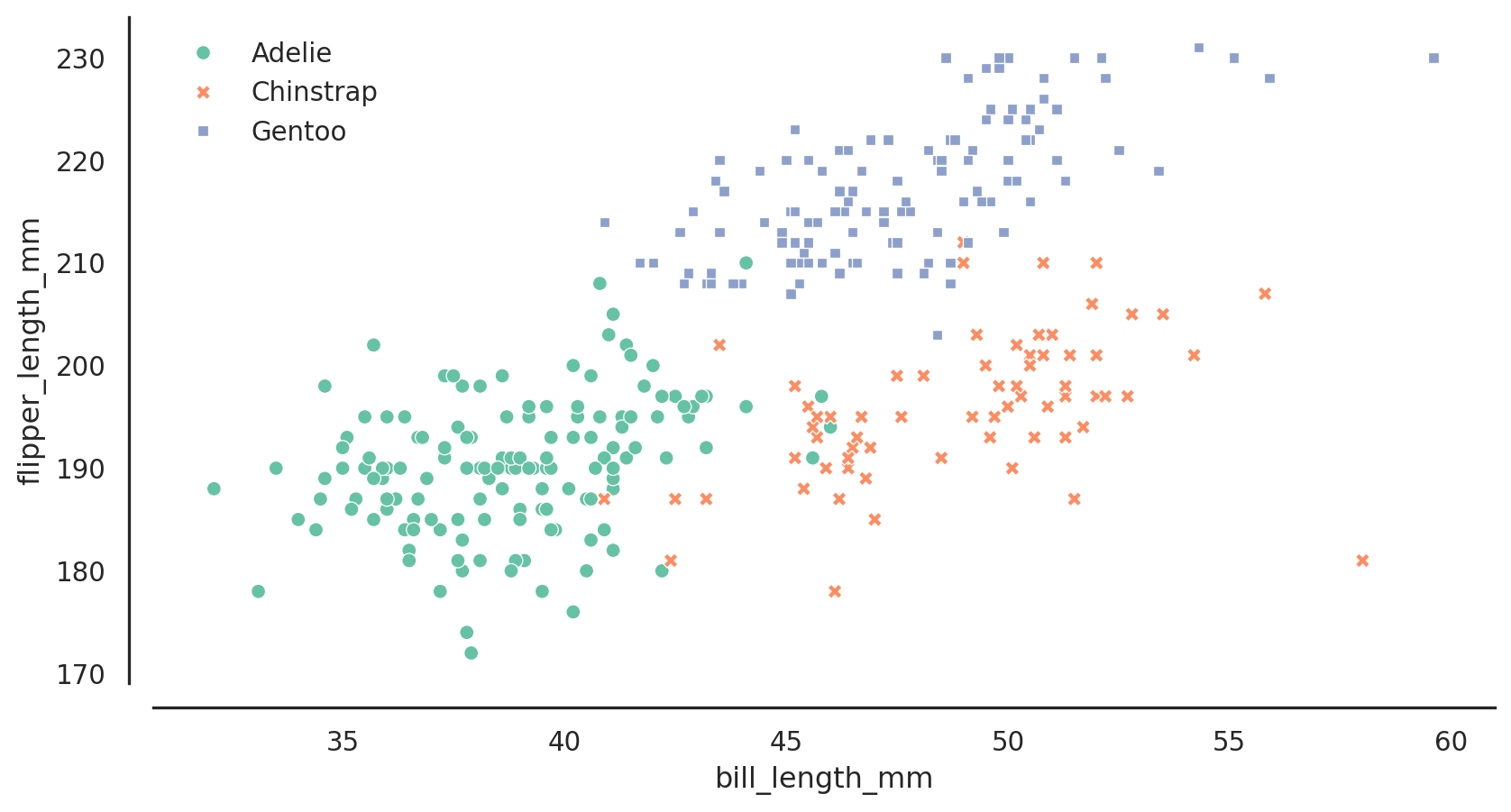
Example
Palmer Penguins

The Palmer Archipelago penguins. Artwork by @allison_horst
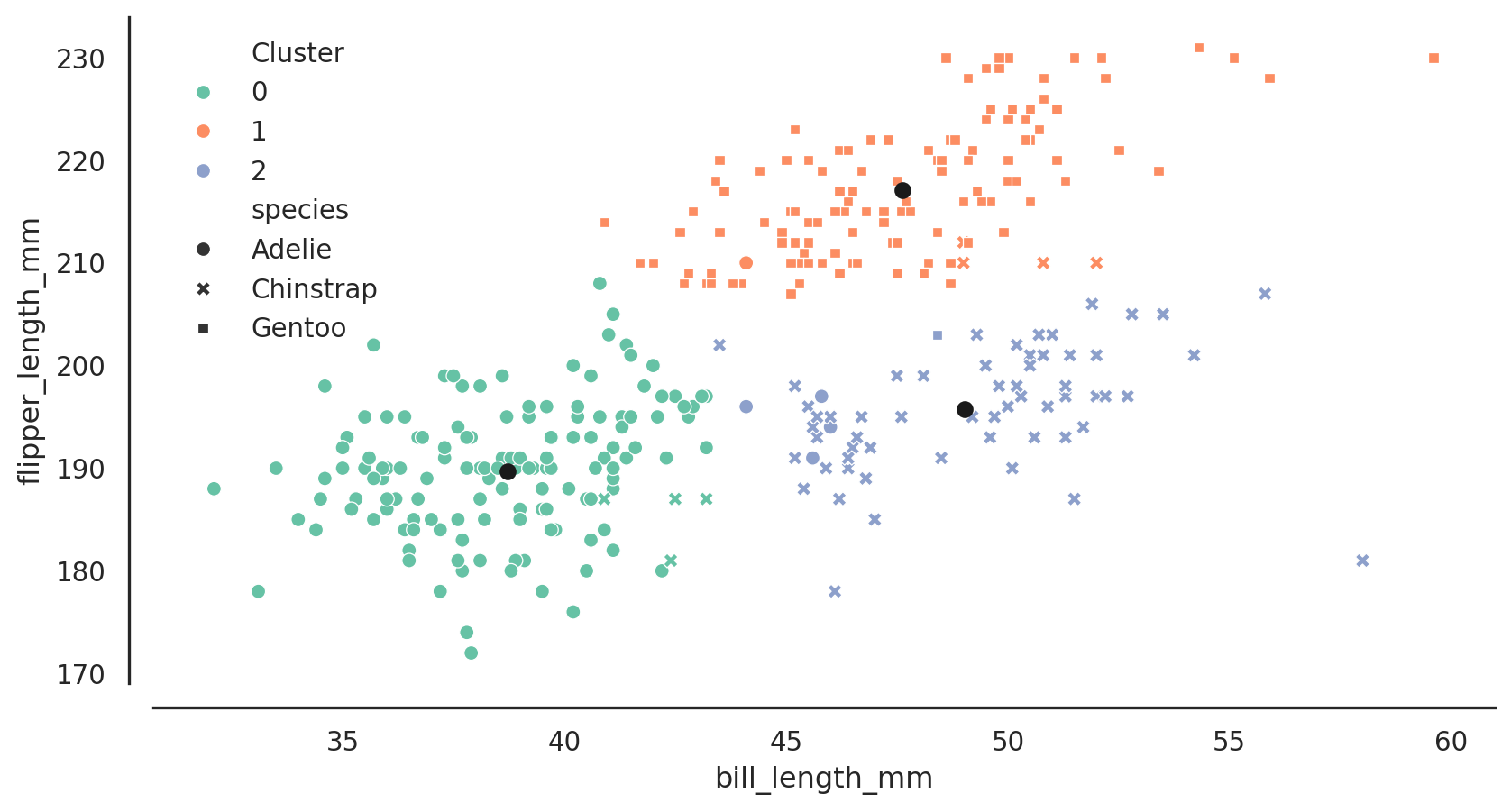
distance-based
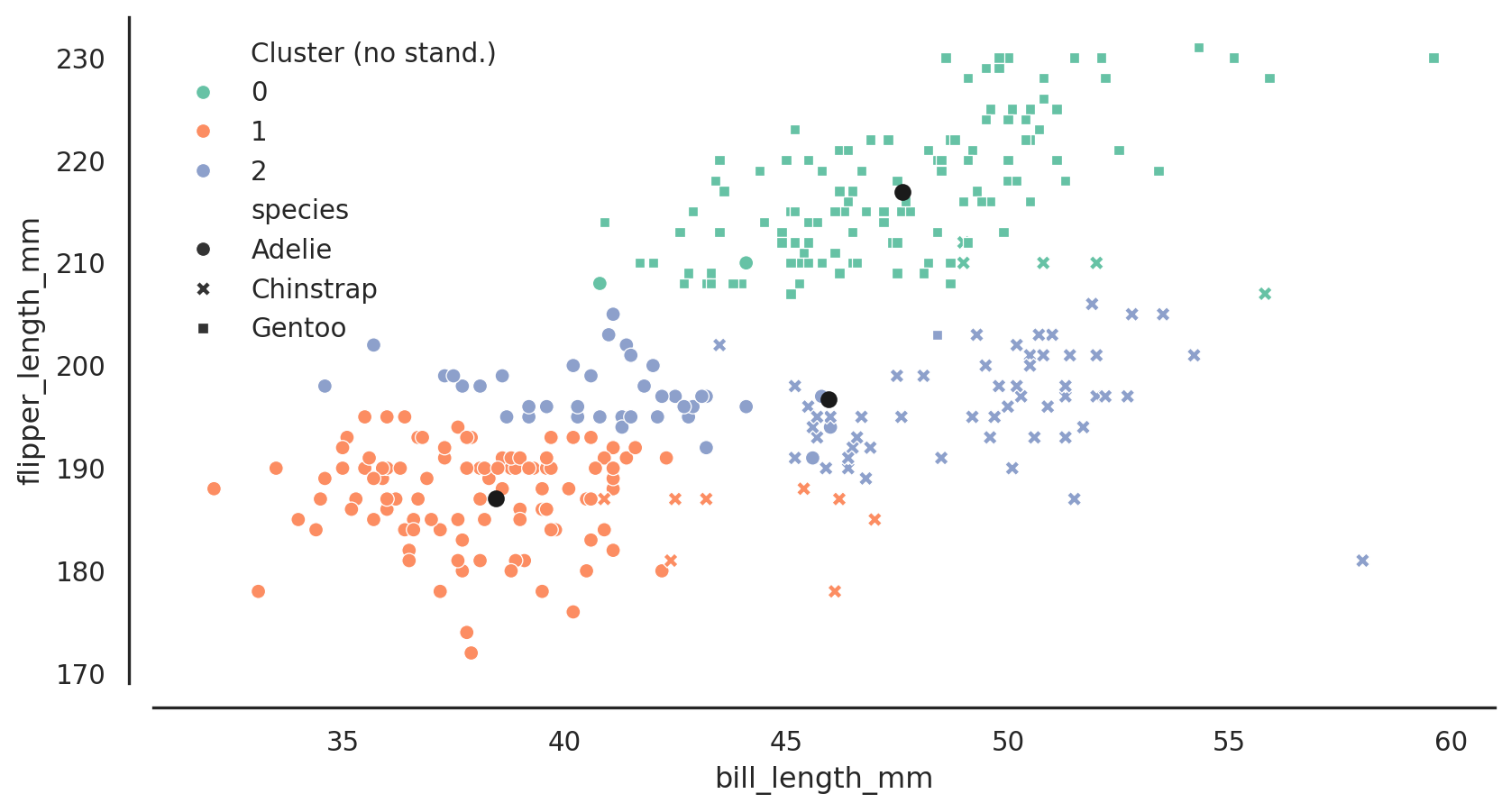
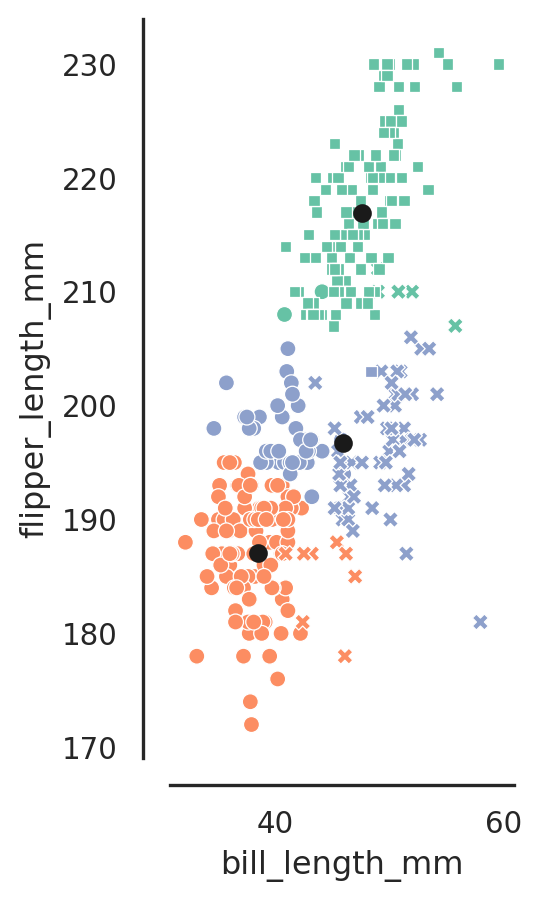
always standardise
Many techniques
Hierarchical clustering
Agglomerative clustering
Spectral clustering
Neural networks (e.g. Self-Organizing Maps)
DBSCAN

Regionalization
Split a dataset into groups of observations that are similar within the group
and dissimilar between groups based on a series of attributes
with the additional constraint that observations need to be spatial neighbours
Aggregating basic spatial units (areas) into larger units (regions)
All the methods aggregate geographical areas into a predefined number of regions while optimizing a particular aggregation criterion
The areas within a region must be geographically connected (the spatial contiguity constraint)
The number of regions must be smaller than or equal to the number of areas
Each area must be assigned to one and only one region
Each region must contain at least one area
All the methods aggregate geographical areas into a predefined number of regions while optimizing a particular aggregation criterion
The areas within a region must be geographically connected (the spatial contiguity constraint)
The number of regions must be smaller than or equal to the number of areas
Each area must be assigned to one and only one region
Each region must contain at least one area
Duque et al. (2007)
Algorithms
Automated Zoning Procedure (AZP)
Arisel
Max-P
Skater
See Duque et al. (2007) for an excellent, though advanced, overview.
import sklearn
![]()